
Представьте: ваша система работает идеально, пока в очередь не прилетает одно-единственное сообщение с кривым JSON. Через секунду один воркер падает, сообщение возвращается в очередь, его подхватывает другой воркер, и тот тоже падает. Так начинается "эффект домино", который за несколько минут складывает весь ваш кластер обработки данных. Знакомая картина? Именно поэтому наблюдаемость очередей - это не просто красивые графики в Grafana, а единственный способ выжить в распределенной системе.
Когда мы говорим об observability (наблюдаемости), мы имеем в виду способность понять, что происходит внутри системы, просто глядя на ее внешние показатели. В случае с очередями это значит не просто знать, что "очередь есть", а понимать, почему сообщения копятся, почему они переповторяются и какие из них стали "ядовитыми".
Понимаем лаги: когда очередь превращается в проблему
Лаг очереди (queue lag) - это разница между последним записанным сообщением и последним обработанным. Если вы видите, что лаг растет, это сигнал: ваши потребители (consumers) не справляются с потоком данных. Но проблема может быть разной.
Иногда это просто всплеск трафика, например, в "черную пятницу". В других случаях - медленный внешний API или тяжелый запрос к базе данных. Важно отслеживать не только общее количество сообщений, но и время жизни одного сообщения в очереди. Если сообщение ждет обработки 10 минут вместо 10 миллисекунд, ваш пользователь, скорее всего, уже закрыл приложение.
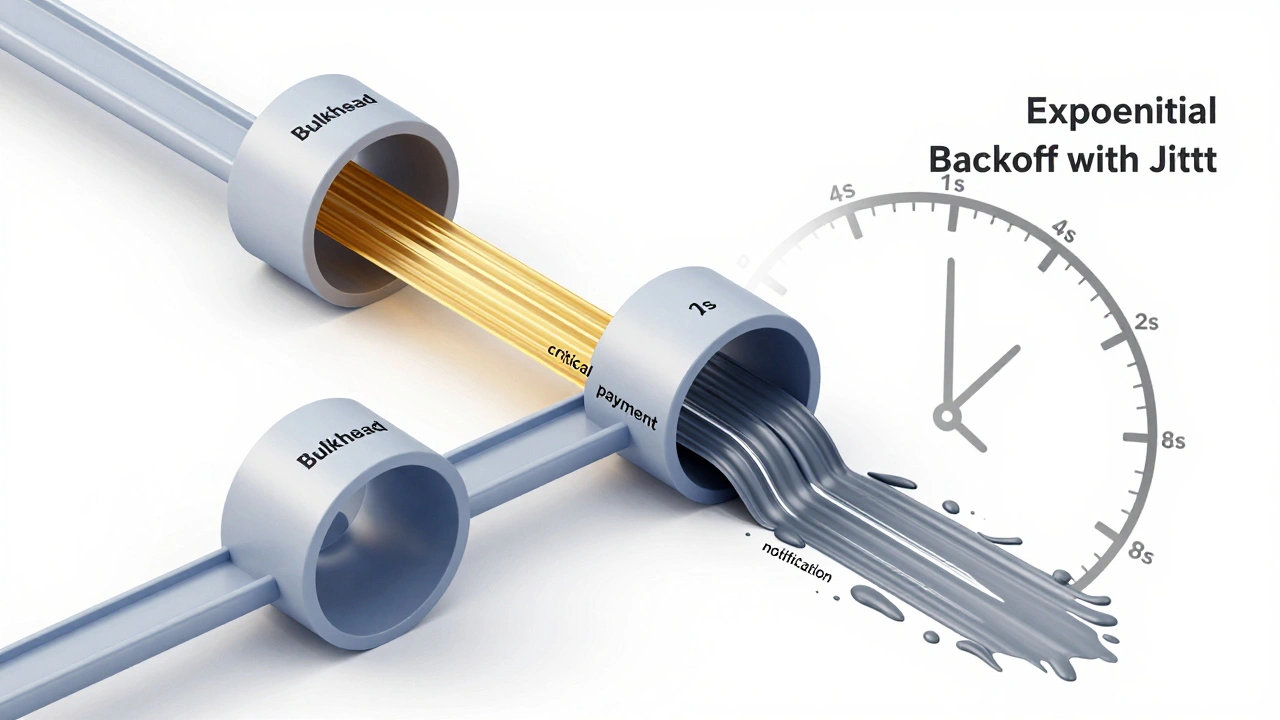
Для борьбы с лагами используют паттерн Bulkhead is изоляционный паттерн, который разделяет ресурсы системы на независимые группы, чтобы сбой в одной части не обрушил всё остальное . Например, вы можете выделить разные очереди для критически важных платежей и для рассылки уведомлений. Так лаг в уведомлениях не заблокирует проведение оплаты.
Искусство ретраев: почему нельзя просто повторять запрос
Когда что-то идет не так (сеть мигнула, сервис временно недоступен), первым делом приходит в голову механизм ретраев (retry). Кажется, что просто попробовать еще раз - отличная идея. Но если 1000 воркеров одновременно начнут повторять запрос к упавшему сервису каждую секунду, они создадут полноценную DDoS-атаку на собственный бэкенд.
Чтобы этого избежать, используйте Экспоненциальный backoff is алгоритм задержки, при котором интервал между попытками повтора увеличивается в геометрической прогрессии . Вместо того чтобы стучаться в дверь каждую секунду, система ждет 1с, затем 2с, 4с, 8с и так далее. Это дает упавшему сервису время «прийти в себя».
Но есть одна проблема: если все клиенты начнут ждать по одной и той же экспоненте, они всё равно ударят по серверу синхронно. Поэтому в дело вступает Jitter - добавление случайного шума к задержке. Вместо ровно 4 секунд один воркер подождет 3.8с, а другой 4.2с. Это размывает нагрузку и спасает систему от повторных коллапсов.
| Стратегия | Как работает | Плюс | Минус |
|---|---|---|---|
| Фиксированная задержка | Всегда пауза N секунд | Просто реализовать | Риск синхронного «шторма» запросов |
| Экспоненциальный backoff | Пауза растет (1, 2, 4, 8...) | Снижает нагрузку на сервис | Может увеличить общее время ожидания |
| Backoff + Jitter | Экспонента + рандом | Максимальная разгрузка системы | Сложнее в отладке и предсказании |
Poison Messages: когда ретраи делают только хуже
Есть ошибки временные (сеть, таймаут), а есть ошибки фатальные. Poison Message is сообщение, которое вызывает ошибку при каждой попытке обработки из-за некорректного содержимого или нарушения бизнес-логики . Если вы настроили бесконечные ретраи, такое сообщение будет бесконечно крутиться в очереди, сжигать ресурсы CPU и забивать логи ошибками.
Как распознать «ядовитое» сообщение? Обычно это видно по одному и тому же идентификатору (ID сообщения), который раз за разом вызывает один и тот же Exception. Здесь ретраи бесполезны: сколько бы раз вы ни пытались разделить строку на ноль или распарсить битый JSON, результат будет одинаковым.
Единственное правильное решение здесь - Dead Letter Queue (DLQ) is специальная очередь для сообщений, которые не удалось обработать после всех попыток ретраев . Вместо того чтобы бесконечно мучить воркер, система перемещает сообщение в DLQ. Теперь оно не мешает остальному потоку, а разработчик может зайти в DLQ, посмотреть на «труп» сообщения, понять, почему оно упало, и либо исправить баг, либо удалить сообщение вручную.
Инструменты контроля: метрики и circuit breaker
Чтобы не гадать на кофейной гуще, нужно собирать конкретные цифры. Что именно мониторить?
- Error Rate: не просто количество ошибок, а их процент от общего числа сообщений. Если 0.1% сообщений падают - это норма. Если 5% - пора просыпаться.
- Retry Count: сколько раз в среднем сообщение обрабатывается, прежде чем завершиться успешно. Рост этого показателя говорит о нестабильности зависимостей.
- DLQ Size: размер очереди мертвых писем. Если она растет - у вас либо баг в коде, либо кто-то прислал вам плохие данные.
Для защиты системы от каскадных сбоев используйте Circuit Breaker is предохранитель, который временно прекращает попытки вызвать сервис, если тот начал систематически отвечать ошибками . Когда «предохранитель» размыкается (состояние Open), система даже не пытается отправить запрос к упавшему API, а сразу возвращает ошибку или отправляет сообщение в DLQ. Это дает зависимому сервису шанс восстановиться без давления со стороны ваших воркеров.

Логирование: как не утонуть в шуме
Типичная ошибка - писать log.error("Message failed") на каждый ретрай. Если у вас 5 попыток на каждое сообщение, а сообщений миллионы, ваши логи превратятся в бесконечный шум. Вы просто не заметите реальную проблему за миллионом предупреждений.
Правильный подход: используйте разные уровни логирования. Первый, второй и третий ретрай - это WARN. Только когда все попытки исчерпаны и сообщение уходит в DLQ, ставьте ERROR.
Логи должны быть структурированными (в JSON). Вместо текста "External API X failed after 3 retries" пишите поля: {"event": "retry_exhausted", "service": "payment_gateway", "attempts": 3, "message_id": "abc-123"}. Это позволит вам за одну секунду построить график в Kibana и увидеть, какой именно сервис тормозит всю систему.
В чем разница между временным сбоем и poison-сообщением?
Временный сбой (transient failure) - это когда сервис недоступен сейчас, но будет доступен через секунду (например, сетевой лаг). Poison-сообщение - это ошибка в самих данных. Сколько бы раз вы ни повторяли попытку, результат будет всегда одинаковым, потому что данные некорректны.
Почему нельзя использовать фиксированный интервал ретраев?
Если произойдет массовый сбой, тысячи воркеров синхронизируются по времени. Они все вместе будут слать запросы ровно через 1, 2, 3 секунды. Это создает «волны» нагрузки, которые могут окончательно «добить» пытающийся восстановиться сервер.
Что делать с сообщениями в DLQ?
Сообщения в Dead Letter Queue требуют анализа. Обычно разработчик изучает причину ошибки, исправляет баг в коде или уточняет формат данных у отправителя, после чего сообщения либо переотправляются в основную очередь, либо удаляются.
Как понять, что пора открывать Circuit Breaker?
Обычно настраивается порог ошибок (например, 50% неудачных запросов за последние 30 секунд). Если порог превышен, предохранитель размыкается. Он переходит в состояние Half-Open через некоторое время, чтобы проверить, восстановился ли сервис, пропуская лишь один тестовый запрос.
Как бороться с лагами, если ресурсов сервера достаточно?
Проверьте время обработки одного сообщения. Возможно, проблема в блокирующих вызовах (I/O), отсутствии индексов в БД или слишком маленьком размере пачки (batch size) при чтении из очереди. Иногда помогает простое увеличение количества параллельных воркеров.
Что делать дальше?
Если вы только начинаете внедрять наблюдаемость, не пытайтесь сделать всё сразу. Начните с настройки DLQ - это спасет вас от падения системы из-за одного «кривого» сообщения. Затем добавьте экспоненциальный backoff с jitter, чтобы ваши ретраи не убивали соседние сервисы. И только потом переходите к сложным метрикам и Circuit Breaker'ам. Помните: чем проще система мониторинга, тем выше вероятность, что ею будут пользоваться, а не игнорировать из-за бесконечных ложных алертов.