Вы запустили модель в продакшен. Она работает быстро, предсказания кажутся точными, а бизнес доволен. Но через месяц или два вы замечаете странности: конверсия упала, количество ложных срабатываний выросло, а команда поддержки завалена жалобами. Модель «разучилась» работать. Это не баг кода - это классическая проблема жизни ML-систем: дрейф данных (Data Drift).
Без должного мониторинга ваша модель становится слепой. В этой статье мы разберем, как построить систему наблюдения за качеством ML-сервиса на Python, чтобы вовремя замечать изменения в данных и автоматически отправлять алерты команде до того, как проблемы ударят по бизнесу.
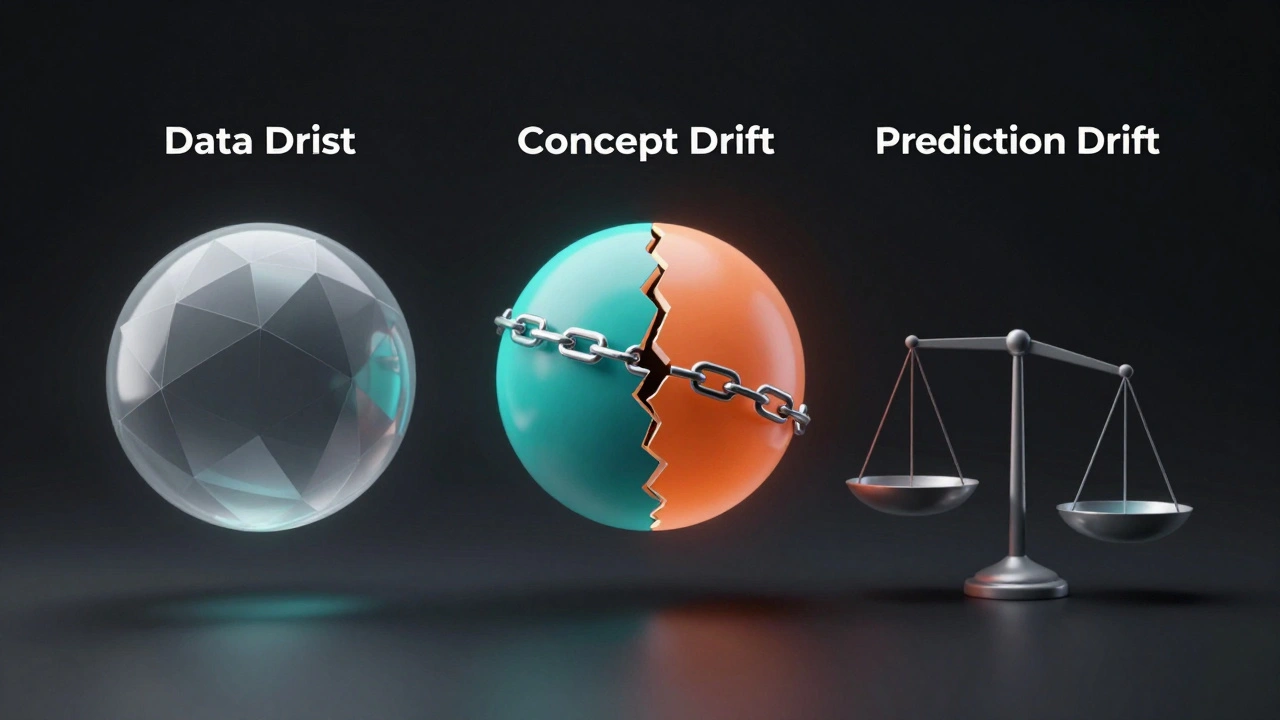
Почему модели деградируют: типы дрейфа
Чтобы бороться с проблемой, нужно понимать её природу. Дрейф - это изменение статистики входных данных или зависимостей между признаками и целевой переменной со временем. В продакшене встречаются три основных типа:
- Data Drift (Feature Drift): Изменяется распределение входных признаков. Например, если ваша модель оценивает кредитоспособность, а экономический кризис резко изменил уровень доходов пользователей, среднее значение признака «доход» сместится. Модель, обученная на старых данных, начнет ошибаться.
- Concept Drift: Меняется сама зависимость между признаками и целью. Представьте рекомендательную систему: раньше люди кликали на яркие баннеры, а теперь предпочитают минимализм. Признаки те же, но правило принятия решений изменилось.
- Prediction Drift: Изменяется распределение выходных предсказаний модели. Если модель спам-фильтра раньше блокировала 5% писем, а вдруг начала блокировать 20%, это сигнал тревоги, даже если вы еще не знаете, почему.
Игнорирование любого из этих типов приводит к снижению качества сервиса. Согласно исследованиям в области MLOps, организации с зрелым мониторингом сокращают простой моделей на 40%. Разница между «мы заметили падение метрик постфактум» и «система предупредила нас о дрейфе за неделю» огромна.
Статистические методы обнаружения дрейфа
Как математически доказать, что данные изменились? Мы используем статистические тесты сравнения распределений. Вот ключевые метрики, которые стоит внедрять:
- PSI (Population Stability Index): Самый популярный метод в индустрии. Он сравнивает распределение признака в обучающей выборке (baseline) и в текущем потоке данных. PSI удобен тем, что его легко интерпретировать:
- 0.0 - 0.1: Незначительные изменения (всё нормально).
- 0.1 - 0.25: Умеренные изменения (требуется внимание).
- > 0.25: Значительные изменения (вероятен дрейф, нужен ретренинг).
- KS-тест (Kolmogorov-Smirnov): Отлично подходит для непрерывных переменных. Он измеряет максимальное расстояние между функциями распределения двух выборок. P-value меньше 0.05 обычно указывает на статистически значимую разницу.
- MMD (Maximum Mean Discrepancy): Более мощный метод, работающий в пространствах воспроизводящего ядра. Хорошо справляется с многомерными данными и сложными распределениями, где простые тесты могут дать сбой.
- Wasserstein Distance: Полезно при работе с «тяжелыми хвостами» распределений, где небольшие сдвиги в экстремальных значениях критичны для бизнеса.
Важно помнить: статистика говорит нам об изменении, но не всегда объясняет причину. Поэтому алерты должны триггериться не только на p-value, но и на бизнес-контекст.
Инструменты на Python: от Evidently AI до Alibi Detect
Писать статистические тесты с нуля на чистом NumPy или SciPy - путь к ошибкам и долгому деплою. Используйте специализированные библиотеки.
Evidently AI - это стандарт де-факто для open-source мониторинга. Он позволяет генерировать HTML-отчеты с визуализацией дрейфа, качества модели и бизнес-метрик. Его главное преимущество - простота интеграции с существующими пайплайнами данных.
| Библиотека | Основной фокус | Тип детекции | Удобство для алертов |
|---|---|---|---|
| Evidently AI | Визуализация и отчеты | Оффлайн (пакетная) | Высокое (через API) |
| Alibi Detect | Обнаружение выбросов и дрейфа | Онлайн и оффлайн | Среднее (требует настройки) |
| Azure ML / SageMaker | Полный цикл MLOps | Встроенный мониторинг | Высокое (нативные алерты) |
Если вам нужна строгая онлайн-детекция в реальном времени, обратите внимание на Alibi Detect. Он поддерживает алгоритмы вроде DDM (Drift Detection Method), которые отслеживают статистику ошибок классификации без хранения всей истории данных. Это критично для высоконагруженных систем, где память ограничена.
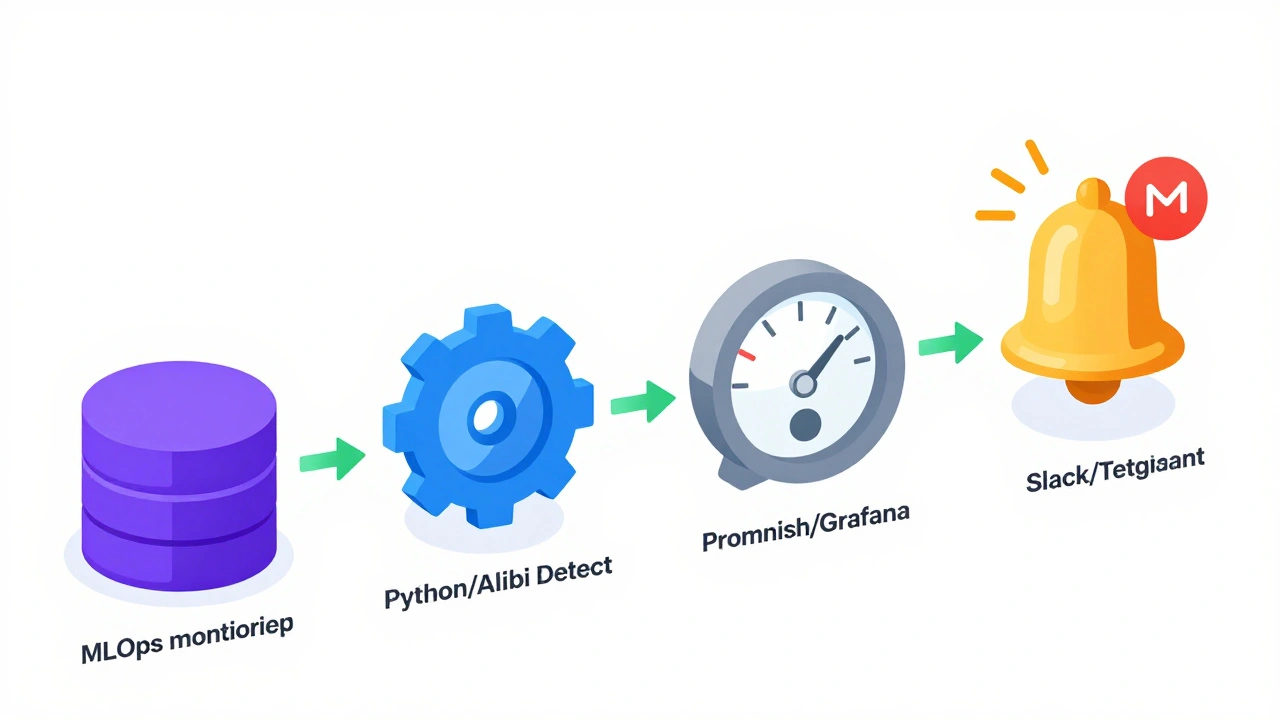
Архитектура системы мониторинга
Эффективный мониторинг - это не один скрипт, а конвейер. Вот как он выглядит на практике:
- Сбор данных: Вы сохраняете входные признаки (features) и выходные предсказания (predictions) вместе с ground truth (если доступен) в хранилище (например, PostgreSQL или Apache Kafka).
- Baseline: У вас есть эталонная выборка - данные, на которых модель показала наилучшие результаты во время валидации.
- Расчет метрик: Периодически (например, раз в час или день) запускается задача, которая берет свежий срез данных и сравнивает его с baseline с помощью PSI или KS-теста.
- Агрегация: Результаты попадают в систему наблюдаемости, такую как Prometheus или Grafana.
- Алертинг: Если метрика превышает порог, система отправляет уведомление в Slack, Telegram или PagerDuty.
Для трассировки запросов и аудита используйте OpenTelemetry. Это поможет связать конкретный инцидент дрейфа с латентностью сервиса или сбоями в инфраструктуре.
Настройка алертов: как избежать усталости команды
Самая большая ошибка новичков в MLOps - настроить алерт на каждое малейшее отклонение. Через неделю ваша команда перестанет читать уведомления. Чтобы этого не произошло, применяйте следующие правила:
- Сегментируйте алерты: Не мониторьте все 50 признаков одинаково. Выделите 3-5 критических фич, которые сильнее всего влияют на бизнес-метрики. Остальные можно проверять реже или с более мягкими порогами.
- Используйте уровни серьезности:
- Informational: Легкие колебания (PSI < 0.1). Просто логируем для анализа трендов.
- Warning: Умеренный дрейф (PSI 0.1-0.25). Уведомляем инженеров, планируем проверку.
- Critical: Сильный дрейф (PSI > 0.25) или падение accuracy более чем на 2%. Требуется немедленное вмешательство и возможный ретренинг.
- Учитывайте сезонность: Алгоритмы должны знать, что в черную пятницу трафик и поведение пользователей отличаются от обычного дня. Используйте адаптивные пороги или скользящие окна сравнения.
- Группируйте уведомления: Если дрейфнули сразу 10 признаков, скорее всего, проблема в источнике данных (ETL-пайплайн сломался), а не в каждом признаке по отдельности. Один алерт «Проблема с источником данных X» лучше, чем десять отдельных сообщений.
Пример практического алерта: «Точность модели классификации упала ниже 85% в течение последнего часа. Зафиксирован Concept Drift. Проверьте последние обновления данных и запустите диагностику.»
Чек-лист для запуска мониторинга
Перед тем как внедрять сложные системы, убедитесь, что у вас есть база:
- [ ] Сохраняются ли входные данные и предсказания в структурированном виде?
- [ ] Есть ли четко определенный baseline (эталонная выборка)?
- [ ] Выбраны ли ключевые признаки для первичного мониторинга?
- [ ] Настроены ли пороги для PSI или других метрик дрейфа?
- [ ] Работает ли канал оповещения (Slack/Email) для критических алертов?
- [ ] Есть ли процесс реагирования: кто и что делает, когда приходит алерт?
Как часто нужно проверять данные на дрейф?
Частота зависит от скорости изменений в вашем бизнесе. Для финансовых транзакций или рекомендательных систем проверка может быть ежечасной или даже реального времени (online drift detection). Для более стабильных процессов, таких как прогнозирование спроса на товары длительного потребления, достаточно ежедневных или еженедельных пакетных проверок (offline drift detection).
Что делать, если алерт сработал, но данных мало?
Статистические тесты ненадежны на маленьких выборках. Если у вас менее 100-200 наблюдений за период, избегайте жестких алертов. Используйте скользящие окна накопления данных или увеличивайте интервал проверки, пока объем выборки не станет достаточным для статистической значимости.
Разница между Data Drift и Concept Drift?
Data Drift - это изменение входных данных (признаков), тогда как Concept Drift - это изменение связи между признаками и целевой переменной. При Data Drift модель может продолжать работать хорошо, если зависимости остались прежними. При Concept Drift модель неизбежно теряет качество, так как старые правила больше не применимы.
Нужен ли мониторинг, если модель переобучается автоматически?
Да, обязательно. Автоматический ретренинг должен triggered именно сигналами мониторинга. Без детекции дрейфа вы либо будете переобучать модель слишком часто (тратя ресурсы), либо слишком редко (теряя качество). Мониторинг определяет «когда», а пайплайн обучения решает «как».
Как выбрать порог для PSI?
Не существует универсального порога. Начните с общепринятых значений (0.1 для warning, 0.25 для critical), затем проведите A/B-тестирование на исторических данных. Посмотрите, сколько ложных срабатываний возникало бы при разных порогах, и скорректируйте их под специфику ваших данных и допустимый уровень риска.