
Представьте ситуацию: ваше приложение только что взлетело. Вчерашний день было всего несколько тестовых пользователей, а сегодня утром вы просыпаетесь от уведомлений о падении сервиса. Сервер не справляется с потоком запросов, база данных зависает, а пользователи жалуются на ошибки 503. Это классический момент истины для любого разработчика или стартапа - время перестать полагаться на один мощный компьютер и начать строить настоящую распределенную систему.
Многие думают, что масштабирование - это просто покупка более дорогого сервера. Но в реальности масштабирование приложения - это процесс изменения архитектуры системы для обработки растущего объема нагрузки без потери производительности. Если вы хотите, чтобы ваш проект рос вместе с аудиторией, а не ломался при каждом скачке трафика, вам нужно понимать разницу между простым добавлением ресурсов и изменением самой структуры работы приложения.
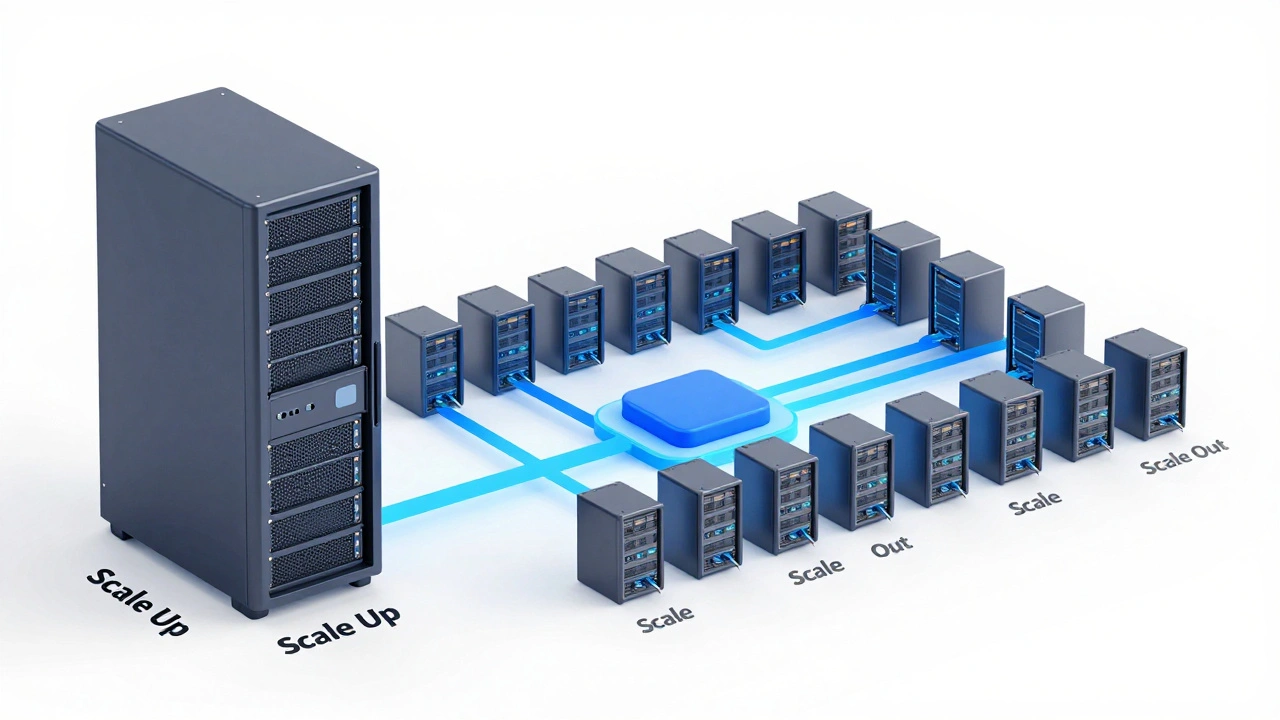
Вертикальное против горизонтального: выбор стратегии
Когда вы запускаете первый прототип, всё обычно живет на одной машине. Это называется монолитной архитектурой. Здесь и веб-сервер, и база данных, и файлы хранятся вместе. Пока пользователей мало, это дешево и удобно. Но как только нагрузка растет, вы сталкиваетесь с первым выбором: как добавить мощности?
Первый вариант - вертикальное масштабирование (Scale Up). Вы берете свой текущий сервер и делаете его «жирнее»: добавляете оперативную память, меняете процессор на многоядерный монстр или переходите на быстрые SSD-диски. Этот подход прост в реализации, потому что код менять не нужно. Однако у него есть жесткий потолок. Нельзя бесконечно увеличивать мощность одного физического устройства. Кроме того, если этот единственный сервер выйдет из строя, вся ваша система умрет. Это так называемая единая точка отказа.
Второй вариант - горизонтальное масштабирование (Scale Out). Вместо того чтобы делать один сервер мощнее, вы добавляете еще один, два, десять таких же серверов. Нагрузка распределяется между ними. Теоретически, вы можете добавлять узлы бесконечно, пока хватает бюджета и административных ресурсов. Этот подход обеспечивает высокую отказоустойчивость: если один сервер упадет, остальные продолжат работать. Именно горизонтальное масштабирование лежит в основе современных облачных платформ вроде AWS или Яндекс.Облако.
| Критерий | Вертикальное (Scale Up) | Горизонтальное (Scale Out) |
|---|---|---|
| Сложность внедрения | Низкая (не требует изменений кода) | Высокая (требует балансировки, репликации) |
| Ограничения | Физические пределы железа | Практически отсутствуют |
| Отказоустойчивость | Низкая (единая точка отказа) | Высокая (резервирование узлов) |
| Стоимость роста | Экспоненциально растет | Линейно растет |
Первый шаг: вынос базы данных
Даже если вы планируете переходить на горизонтальное масштабирование, не стоит сразу распыляться. Первый логичный шаг при росте нагрузки - разделить приложение и базу данных. Когда они живут на одной машине, база данных забирает себе всю оперативную память и CPU, оставляя веб-сервер голодным. Или наоборот: тяжелые вычисления приложения блокируют доступ к данным.
Перенос базы данных на отдельный сервер или использование управляемых сервисов (например, Amazon RDS или DigitalOcean Managed Database) решает эту проблему. Да, это стоит дороже, чем самостоятельный хостинг, но вы получаете автоматическое резервное копирование, реплику для чтения и защиту от простоев. База данных становится независимым компонентом, который можно оптимизировать отдельно от логики приложения.
Балансировка нагрузки: сердце горизонтального масштабирования
Как только вы решили запустить несколько копий вашего приложения на разных серверах, возникает вопрос: кто решит, какой сервер должен обработать входящий запрос пользователя? Вот тут на сцену выходит балансировщик нагрузки (Load Balancer).
Балансировщик работает как диспетчер. Он стоит перед вашими серверами и принимает все входящие соединения. Затем он перенаправляет каждый запрос на тот сервер, который сейчас меньше всего загружен. Популярные решения включают NGINX, HAProxy или облачные балансировщики вроде AWS ALB.
Без балансировщика горизонтальное масштабирование невозможно. Пользователи должны иметь дело с одним адресом (доменом), а внутри этот адрес должен динамически распределять работу между десятками инстансов. Балансировщик также может выполнять проверки здоровья: если один сервер «завис», балансировщик перестает отправлять на него трафик, пока администратор не исправит проблему.
Проблема состояния: Session Stickiness и Redis
Здесь кроется главная ловушка для новичков. Представьте, что пользователь вошел в систему на первом сервере. Его сессия (данные о том, что он авторизован) сохранена в памяти этого конкретного сервера. Если следующий запрос этого пользователя попадет на второй сервер благодаря балансировщику, второй сервер не узнает пользователя и потребует повторного входа.
Есть два пути решения этой проблемы:
- Session Stickiness (липкие сессии): Балансировщик запоминает IP-адрес клиента и всегда направляет его на один и тот же сервер. Это простое решение, но оно нарушает принцип равномерного распределения нагрузки. Один сервер может перегрузиться, пока другие простаивают.
- Внешнее хранилище сессий: Все данные сессий хранятся не в памяти серверов приложения, а в быстром внешнем хранилище, таком как Redis или Memcached. Любой сервер приложения может обратиться к этому хранилищу и получить информацию о пользователе. Это позволяет масштабировать пул серверов произвольно, не теряя контекст пользователя.
Для серьезных проектов второй вариант является стандартом де-факто. Он делает ваши серверы приложения «безопасными» (stateless), что критически важно для автоматического масштабирования.
Репликация базы данных: Master-Slave архитектура
Со временем база данных становится главным узким местом. Запросы на запись (INSERT, UPDATE) медленнее, чем запросы на чтение (SELECT). И в большинстве приложений чтений значительно больше, чем записей. Например, интернет-магазин: тысячи людей смотрят товары (чтение), но только единицы оформляют заказ (запись).
Чтобы разгрузить основную базу, используется репликация. Создается главный сервер (Master), куда идут все записи. Параллельно создаются копии (Replicas или Slaves), которые зеркально копируют данные с мастера. Веб-серверы приложения научаются направлять запросы на чтение на реплики, а на запись - только на мастер.
Это позволяет линейно увеличивать пропускную способность системы на чтение, просто добавляя новые серверы-реплики. Однако помните: репликация не решает проблему медленных записей. Для этого нужна более глубокая оптимизация запросов или шардирование (разделение базы на части).

Разделение компонентов: путь к микросервисам
Когда приложение становится достаточно большим, одна команда кода начинает делать слишком много вещей: обрабатывает платежи, генерирует отчеты, управляет чатом в реальном времени. Эти функции имеют совершенно разные требования к нагрузке. Чат может требовать постоянных соединений WebSocket, а генерация отчетов - огромных всплесков CPU раз в сутки.
Правильная стратегия масштабирования здесь - выделение отдельных служб. Код обработки WebSocket выносится в отдельный сервис, который масштабируется независимо от основного API. Фоновые задачи (отправка email, обработка видео) переносятся в очередь задач, такую как Apache Kafka или RabbitMQ.
Такой подход превращает монолит в микросервисную архитектуру. Каждый микросервис отвечает за одну конкретную функцию и может быть написан на разных языках, использовать разные базы данных и масштабироваться независимо. Да, это усложняет разработку и требует внедрения систем мониторинга и трассировки, но это единственная цена за возможность гибкого управления ресурсами в крупных системах.
Автоматизация и контейнеризация
Управлять вручную десятью серверами сложно. А сотней - невозможно. Поэтому современное масштабирование неразрывно связано с контейнеризацией. Инструменты вроде Docker позволяют упаковать приложение со всеми его зависимостями в единый образ. Оркестраторы, такие как Kubernetes, автоматически управляют этими контейнерами.
Kubernetes может следить за нагрузкой на ваши сервисы. Если CPU определенного сервиса превышает 70%, оркестратор автоматически создает новый контейнер этого сервиса и подключает его к балансировщику. Когда нагрузка спадает, лишние контейнеры удаляются. Это называется автоскейлингом (Auto Scaling). Он экономит деньги, так как вы платите только за ресурсы, которые реально используются в пиковые моменты.
Когда пора начинать масштабировать приложение?
Не стоит гнаться за сложной архитектурой с первого дня. Масштабировать нужно тогда, когда вы начинаете видеть симптомы перегрузки: рост времени ответа сервера выше допустимого порога (например, более 2 секунд), частые падения базы данных из-за нехватки памяти или увеличение количества ошибок 5xx в логах. Также сигналом служит рост числа одновременных пользователей, который приближается к лимитам вашего текущего оборудования.
Чем горизонтальное масштабирование лучше вертикального?
Горизонтальное масштабирование предлагает практически неограниченный потенциал роста и высокую отказоустойчивость. При выходе из строя одного сервера система продолжает работать. Вертикальное масштабирование ограничено физическими возможностями одного компьютера и создает единую точку отказа. Кроме того, стоимость мощных серверов растет экспоненциально, тогда как добавление обычных серверов дешевле.
Нужен ли мне балансировщик нагрузки для двух серверов?
Да, даже для двух серверов балансировщик необходим. Без него вы не сможете равномерно распределять трафик и обеспечивать отказоустойчивость. Простые балансировщики, такие как NGINX, легко настроить и они эффективно решают задачу распределения запросов между несколькими инстансами приложения.
Как решить проблему сессий при горизонтальном масштабировании?
Лучшее решение - использовать внешнее хранилище сессий, такое как Redis. Это позволяет хранить данные авторизации пользователя отдельно от серверов приложения. Тогда любой сервер сможет обработать запрос любого пользователя, так как все они обращаются к одному источнику правды. Альтернатива - настройка липких сессий на балансировщике, но это менее гибкое решение.
Что такое репликация базы данных и зачем она нужна?
Репликация - это создание копий основной базы данных. Главный сервер (Master) принимает все записи, а дополнительные серверы (Replicas) копируют эти данные. Приложение направляет запросы на чтение на реплики, что значительно снижает нагрузку на мастер и увеличивает общую скорость работы системы, особенно при большом количестве читателей.