
Пользователь нажимает кнопку «Купить», страница зависает, появляется ошибка 502 Bad Gateway. Сервер не умер полностью, но он перегружен или у него «зависла» база данных. Если ваш балансировщик нагрузки настроен неправильно, этот пользователь будет ждать ответа минуту, пока таймаут не истечет, или получит ошибку сразу, даже если соседний сервер мог бы обработать запрос за миллисекунды. Разница между «сервис работает стабильно» и «постоянные инциденты» часто кроется не в мощности железа, а в двух вещах: как быстро система понимает, что сервер сломался (health-check), и сколько времени она готова ждать ответа (таймауты).
В этой статье мы разберем, как правильно настроить проверки состояния и временные ограничения для бэкендов, чтобы избежать флаппинга, лишних ожиданий и потери трафика. Мы посмотрим на конкретные примеры конфигураций для Nginx, популярного веб-сервера и обратного прокси, HAProxy, высокопроизводительного балансировщика нагрузки и обсудим логику расчета этих значений.
Зачем нужны health-checks и таймауты?
Балансировщик нагрузки, компонент, распределяющий входящий трафик между несколькими серверами - это не просто распределитель пакетов. Это первый рубеж защиты вашего приложения от сбоев. Его главная задача - отправить запрос только на тот сервер, который действительно может его обработать.
Если балансировщик отправляет трафик на «больной» сервер, происходят две вещи:
- Рост задержек (latency): Запрос висит в очереди или обрабатывается медленно, ухудшая опыт всех пользователей.
- Каскадные отказы: Перегруженный сервер перестает отвечать другим сервисам, что может вызвать цепную реакцию сбоев во всей архитектуре.
Health-check, периодическая проверка доступности бэкенда позволяет балансировщику заранее узнать о проблеме и исключить сервер из ротации до того, как туда попадет реальный пользовательский запрос. Таймауты же ограничивают время ожидания ответа, предотвращая бесконечное «зависание» соединений.
Активные и пассивные проверки состояния
Существует два основных подхода к мониторингу здоровья бэкендов. В идеале нужно использовать оба одновременно.
Активные health-checks (Active)
Балансировщик периодически отправляет специальные тестовые запросы к серверам, независимо от того, есть ли реальный трафик от пользователей. Обычно это простой HTTP-запрос к эндпоинту вроде /healthz или /status.
Как это работает:
- Балансировщик отправляет запрос.
- Ожидает ответ с кодом 200-399.
- Если ответов нет или код ошибки - помечает сервер как подозрительный.
- После серии неудач (unhealthy threshold) исключает сервер из пула.
Для настройки активных проверок важно понимать три параметра:
- Интервал (interval): Как часто проверяем? Типичные значения: 1-10 секунд. Слишком частые проверки могут нагружать слабые серверы.
- Таймаут (timeout): Сколько ждем ответ? Обычно 0.5-2 секунды. Должен быть меньше, чем таймаут самого приложения.
- Пороги (thresholds): Сколько успешных проверок подряд нужно, чтобы считать сервер здоровым (rise/healthy), и сколько неудачных, чтобы считать мертвым (fall/unhealthy). Стандартная практика: 2 успешных / 3 неудачных.
Пассивные health-checks (Passive)
Этот метод реагирует на ошибки реальных пользовательских запросов. Балансировщик не опрашивает сервер отдельно, а смотрит на результаты проксирования.
В Nginx это реализуется через директивы max_fails и fail_timeout. Логика проста: если сервер вернул ошибку (например, 502 или 504) или не ответил в течение таймаута определенное количество раз (max_fails) за определенный период (fail_timeout), то он признается неработоспособным на срок fail_timeout.
Пример логики пассивной проверки:
max_fails=3: Допускаем 3 ошибки подряд.fail_timeout=30s: Ошибки считаются в окне 30 секунд. После превышения порога сервер банится на 30 секунд.
Пассивные проверки хороши тем, что они не создают лишнего трафика, но плохи тем, что реагируют с задержкой - сначала должны ошибиться реальные пользователи.
Анатомия таймаутов бэкендов
Многие разработчики думают, что существует один общий таймаут на весь запрос. На самом деле, в сетевых протоколах таймауты разбиты на этапы. Понимание этой разницы критически важно для отладки.
В большинстве балансировщиков выделяют следующие типы таймаутов:
| Тип таймаута | Описание | Типичное значение |
|---|---|---|
| Connect Timeout | Время на установление TCP-соединения с бэкендом. Если порт закрыт или сервер перегружен, соединение не создается. | 1-5 секунд |
| Sending Timeout | Максимальное время между двумя операциями записи данных в сокет бэкенда. Если данные не уходят, соединение разрывается. | 5-60 секунд |
| Reading Timeout | Максимальное время между двумя операциями чтения данных из сокета бэкенда. Самый важный таймаут для медленных запросов. | 10-120 секунд |
| Request Timeout | Общее время на обработку всего запроса клиентом (не всегда поддерживается напрямую в L4/L7 прокси). | Зависит от бизнес-логики |
Важный нюанс: таймауты балансировщика должны быть согласованы с таймаутами самого приложения. Если ваше приложение на Go или Python убивает запрос через 10 секунд, а балансировщик ждет 30 секунд, вы получите ошибку соединения раньше, чем ожидаете. И наоборот, если балансировщик рвет соединение через 5 секунд, а приложение обрабатывает тяжелую задачу 10 секунд, пользователь получит обрыв без полезного ответа.
Практическая настройка: Nginx vs HAProxy
Давайте посмотрим, как эти концепции выглядят в коде двух самых популярных инструментов.
Настройка в Nginx
В бесплатной версии Nginx активные health-checks отсутствуют (они есть в платном NGINX Plus). Поэтому основной упор делается на пассивные проверки и правильные таймауты.
upstream backend {
server 10.0.0.1:8080;
server 10.0.0.2:8080;
# Пассивные health-checks
max_fails=3; # Количество ошибок для бана
fail_timeout=30s; # Окно подсчета ошибок и длительность бана
}
server {
listen 80;
# Таймауты
proxy_connect_timeout 5s; # Установка TCP-соединения
proxy_send_timeout 10s; # Отправка данных бэкенду
proxy_read_timeout 30s; # Ожидание ответа от бэкенда
# Ретраи (повторные попытки)
proxy_next_upstream error timeout http_502 http_503 http_504;
proxy_next_upstream_tries 2; # Максимум 2 попытки
proxy_next_upstream_timeout 10s; # Общее время на все ретраи
}Обратите внимание на proxy_next_upstream_timeout. Это глобальное ограничение времени для всех попыток обработки запроса. Если первая попытка заняла 8 секунд, а вторая 3, суммарно выйдет 11 секунд, и запрос будет прерван, даже если отдельные таймауты были больше.
Настройка в HAProxy
HAProxy предлагает более гибкую модель с встроенными активными проверками.
defaults
mode http
timeout connect 5s
timeout client 30s
timeout server 30s
timeout check 2s
backend my_app
balance roundrobin
option httpchk GET /healthz
server web1 10.0.0.1:8080 check inter 5s rise 2 fall 3 slowstart 30s
server web2 10.0.0.2:8080 check inter 5s rise 2 fall 3 slowstart 30sРазбор параметров:
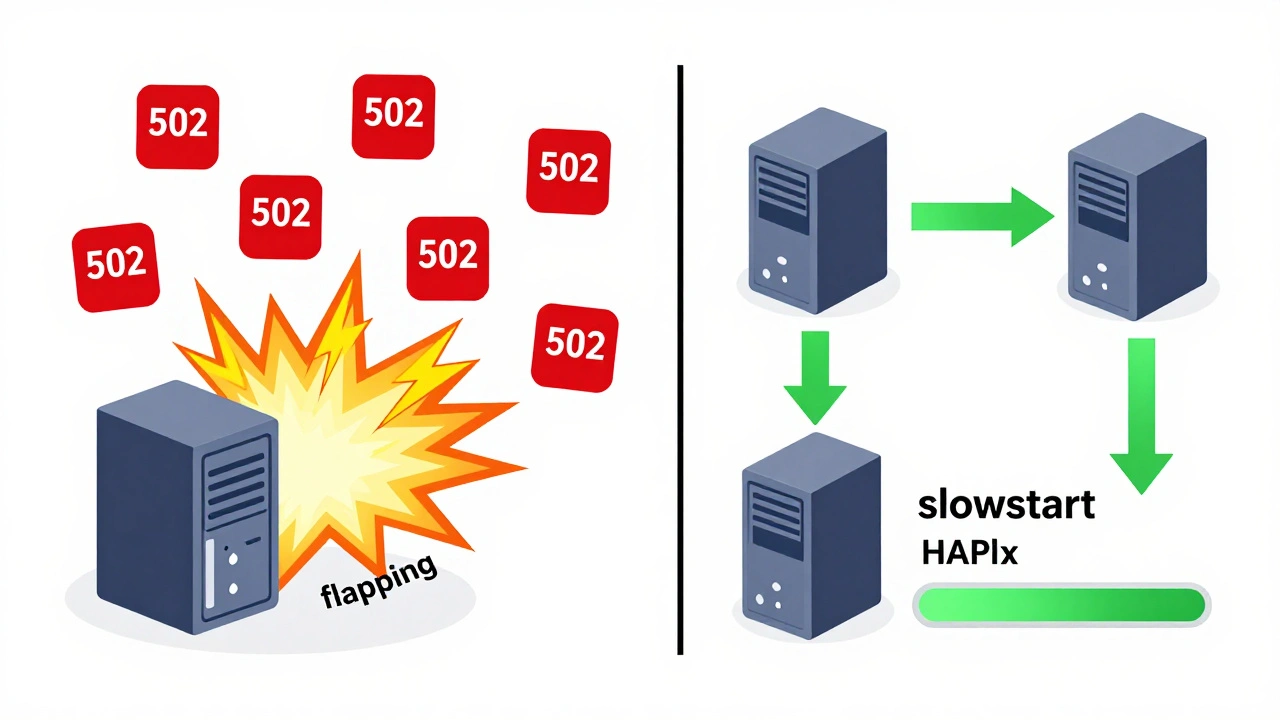
inter 5s: Интервал между health-checkами.rise 2: Сервер считается рабочим после 2 успешных проверок подряд.fall 3: Сервер считается нерабочим после 3 неудачных проверок подряд.slowstart 30s: Новая функция! После возврата в строй сервер получает трафик постепенно в течение 30 секунд. Это защищает от ситуации, когда только что перезагруженный сервер мгновенно захлебывается от потока запросов.
Стратегия расчета таймаутов и ретраев
Как выбрать числа, которые не будут ни слишком агрессивными, ни слишком расслабленными? Существует простая формула, рекомендуемая инженерами SRE.
Предположим, ваше бизнес-требование таково: пользователь не должен ждать ответ дольше 1 секунды (это наш max). Вы хотите гарантировать, что балансировщик попробует отправить запрос на другой сервер, если первый не отвечает.
Формула для таймаута одной попытки (per_try_timeout):
per_try_timeout = max / количество_попыток
Если вы хотите сделать 2 попытки (первый сервер + один ретрай на второй сервер):
per_try_timeout = 1 сек / 2 = 0.5 сек
Это означает, что каждый отдельный таймаут на чтение/отправку к бэкенду должен быть установлен примерно в 500 мс. Если сервер не отвечает за полсекунды, балансировщик немедленно переключается на следующий.
Важное предупреждение про ретраи: Повторные попытки безопасны только для идемпотентных запросов (GET, HEAD). Для POST или PUT (например, создание заказа или списание средств) ретрай может привести к дублированию операции. В таких случаях лучше возвращать ошибку клиенту, чем рисковать данными.
Частые ошибки и как их избежать
Даже при правильной теории на практике встречаются типичные ловушки.
- Флаппинг (Flapping): Сервер то включается, то выключается из ротации каждые несколько секунд. Это происходит, если пороги слишком низкие (например, 1 ошибка = ban) или интервалы проверок слишком короткие. Решение: увеличьте
fallдо 3-5 и добавьтеjitter(случайную задержку) к интервалам проверок, чтобы все балансировщики не стучали в сервер одновременно. - «Мертвый» health-endpoint: Проверка
/healthzвозвращает 200 OK, потому что процесс запущен, но база данных недоступна. Пользователи получают ошибку 500 при реальном запросе. Решение: делайте health-check «умным». Он должен проверять критические зависимости (подключение к БД, очереди), но делать это быстро (менее 100 мс). - Недостаточный таймаут подключения: Если сеть перегружена, TCP-рукопожатие может занять больше времени, чем обычно. Установите
connect_timeoutчуть выше среднего пинга между серверами, но не больше 5 секунд, чтобы не держать открытыми тысячи полу-соединений. - Отсутствие drain-процедуры: При обновлении сервера нельзя просто убить процесс. Нужно сначала исключить его из балансировки (через health-check или API), подождать, пока текущие запросы завершатся, и только потом останавливать. Иначе пользователи получат обрыв соединения.
Заключение
Балансировка нагрузки - это не «установил и забыл». Health-checks и таймауты требуют постоянной калибровки под реальные метрики вашей системы. Начните с консервативных значений (интервал 5 секунд, таймауты 2-5 секунд), затем уменьшайте их, наблюдая за поведением под нагрузкой. Используйте инструменты chaos-engineering, чтобы искусственно убивать бэкенды и смотреть, как быстро система восстанавливается. Помните: цель не в том, чтобы никогда не падать, а в том, чтобы падать незаметно для пользователя.
Какой интервал health-check считается оптимальным?
Для большинства веб-приложений интервал от 2 до 5 секунд является хорошим балансом между скоростью обнаружения сбоя и нагрузкой на серверы. Для критичных систем можно снижать до 1 секунды, но следует учитывать нагрузку, создаваемую самими проверками.
В чем разница между active и passive health-check?
Active health-check инициируется самим балансировщиком регулярно, независимо от наличия пользователей. Passive health-check основан на анализе ошибок реальных запросов от клиентов. Active позволяет предотвратить отправку трафика на сломанный сервер, passive - реагирует на уже произошедшие сбои.
Что такое флаппинг в контексте балансировки нагрузки?
Флаппинг - это частое переключение сервера между состояниями «работает» и «не работает». Это происходит, когда пороги срабатывания слишком чувствительны, и кратковременные задержки воспринимаются как полный отказ. Это создает нестабильность и дополнительную нагрузку.
Нужно ли настраивать разные таймауты для разных типов запросов?
Да, желательно. Быстрые API-запросы (JSON) могут иметь таймауты в 1-2 секунды, тогда как генерация отчетов или загрузка файлов может требовать 30-60 секунд. В современных прокси (как Envoy или NGINX Plus) можно задавать таймауты на уровне маршрутов (routes).
Как избежать дублирования операций при использовании ретраев?
Используйте ретраи только для идемпотентных методов (GET, HEAD, OPTIONS). Для изменяющих состояние методов (POST, PUT, DELETE) либо отключайте ретраи на уровне балансировщика, либо реализуйте идемпотентность на уровне приложения (например, используя уникальные ID транзакций).